

Photo by Glenn Carstens-Peters on Unsplash
Build a Stackoverflow-like Question Recommendation for the Chatbot
one NLP solution using python, word2vec and WMD-similarity


People who have ever asked questions on the stackoverflow.com or quora.com, must noticed that it will prompt with similar questions asked by the others, when you are typing.
This feature is genial and useful. For me, it is like a createOrGet() function, similar to the well-known createOrUpdate() function when updating a database. The reason I mention this, is because there is a similar problem to solve for the chatbot world.
A lot of the chatbot out there are using intents to answer the questions, Intents are basically pre-trained classifications of topics which could be asked by the users. But what if there is no existing intents that are able to cover the topic of a question? Of course we could improve or extend the intents step by step later, or simply let the user rearrange their questions. But is there a way that could guide the users to ask a "proper question" before any improvements on the server side? One solution I can imagine could be the "createOrGet()" service of the stackoverflow.com
Imagine this scene, when an employee asked a short question with less keywords in the Human Resource department chatbot "I want to quit", unfortunately the intent about this topic is not trained well enough. Unless it's by design... we should at least try to avoid to make the user reformulate the question to improve the user experience.
For the analytical purpose, we often save the targeted and untargeted questions In the database. So there should be a bunch of answered questions which could be used for training a quick-model.
The Word Mover's Distance Similiarity could be a proper tool for reaching the purpose. It is able to get the “distance” between two documents, even they have no words in common. We can use Word2vec to train a model, this model will be applied to the WMD to compare distance of each word vectors in all sentences and then give out a sorted list of the known sentences with the highest similarity at the top of the list.
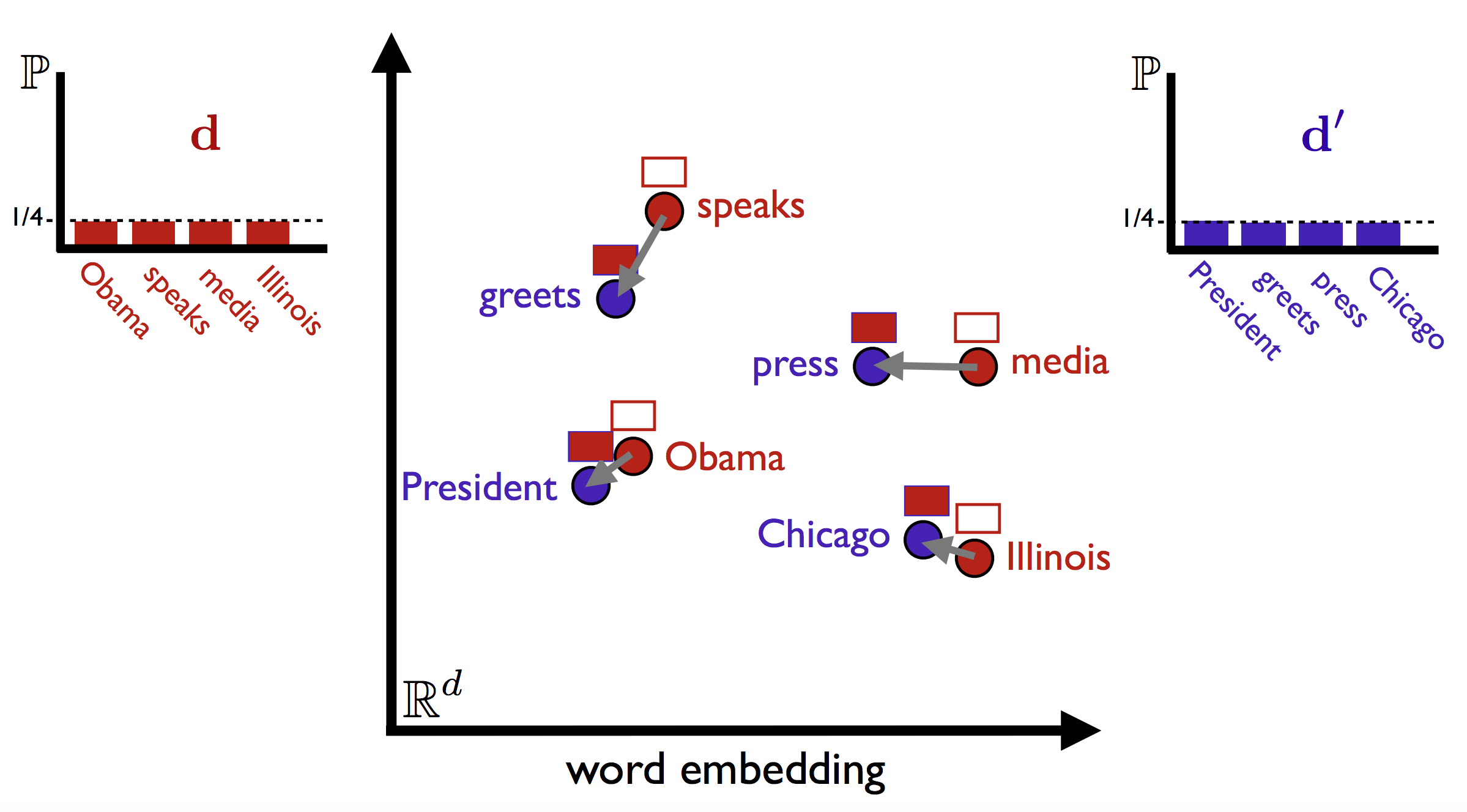
Different as the TF-IDF and KMeans combination, which can only find the similar sentences containing exactly the same words. Word2vec with WMD can find out sentence like: ‘Obama speaks to the media in Illinois’, and ‘The president greets the press in Chicago’ are highly similar.
The architecture of our quick solution looks like the firgure below. We can firstly download a pre-trained word2vec data model like google news, or train the model using a very big corpus of your own. It could take some time, but advantage is that you can control the content and the threshold for getting a better model that fit your needs.
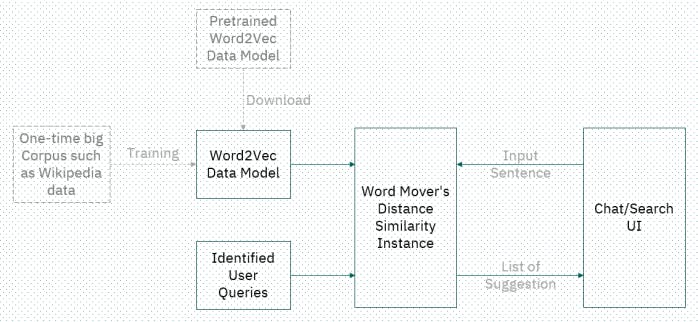
Once you get the word2vec data model, half works would have been done. The next step is to prepare your user query list. Like mentioned above, a chatbot project will normally have the questions list saved in the database for the analytical purpose, but you can also create your own for test.
Talk is cheap, let me show you some code.
Backend
import os
# Import and download stopwords from NLTK.
from nltk.corpus import stopwords
from nltk import download
from nltk import word_tokenize
from gensim.models import KeyedVectors
from gensim.similarities import WmdSimilarity
download('stopwords') # Download stopwords list.
download('punkt') # Download data for tokenizer.
stopwordsExtra = 'hi hello please need want today'
class Recommendation(object):
def __init__(self, language='english', num_best=10, filename='data/UserQueries.txt'):
self.stop_words = list(set(stopwords.words(language) + word_tokenize(stopwordsExtra)))
self.__createWmdInstance(filename, num_best)
def __preprocess(self, doc):
"""Pre-processing a document"""
doc = doc.lower() # Lower the text.
doc = word_tokenize(doc) # Split into words.
doc = [w for w in doc if not w in self.stop_words] # Remove stopwords.
doc = [w for w in doc if w.isalpha()] # Remove numbers and punctuation.
return doc
def __loadFile(self, filePath):
with open(filePath, 'r', encoding="utf8") as corpus:
lines = list(set(corpus.read().lower().splitlines()))
return lines
def __createWmdInstance(self, askedQueryFile, num_best):
# wmd_corpus, with no pre-processing (so we can see the original documents).
self.documents = self.__loadFile(askedQueryFile)
# Documents to run queries against (only one restaurant).
wmd_corpus = [self.__preprocess(query) for query in self.documents]
# Train Word2Vec on all the restaurants.
pretrained = 'data/GoogleNews-vectors-negative300.bin.gz'
if not os.path.exists(pretrained):
raise ValueError("SKIP: You need to download the google news model")
model = KeyedVectors.load_word2vec_format(pretrained, binary=True)
# Initialize WmdSimilarity.
self.instance = WmdSimilarity(wmd_corpus, model, num_best)
def get_recommend_score(self, userQuery):
preprocessed = self.__preprocess(userQuery)
# A query is simply a look-up in the similarity class.
sims = self.instance[preprocessed]
docu = self.documents[sim[0]]
result = ["{0:.2f}".format(sim[1]*100)+'%:'+docu for sim in sims]
return result
def get_recommend(self, userQuery):
preprocessed = self.__preprocess(userQuery)
# A query is simply a look-up in the similarity class.
sims = self.instance[preprocessed]
result = [self.documents[sim[0]] for sim in sims]
def get_response(self, userQuery):
return 'answer to: '+userQuery
Frontend
from flask import Flask, render_template, request, jsonify
from recommendation import Recommendation
from flask_cors import CORS, cross_origin
app = Flask(__name__)
cors = CORS(app)
app.config['CORS_HEADERS'] = 'Content-Type'
recommend = Recommendation()
@app.route("/")
def home():
return render_template("index.html")
@cross_origin()
@app.route("/recommend")
def get_bot_recommend():
userText = request.args.get('query')
return jsonify(english_bot.get_recommend(userText))
@cross_origin()
@app.route("/recommend_score")
def get_bot_recommend_score():
userText = request.args.get('query')
return jsonify(recommend.get_recommend_score(userText))
@cross_origin()
@app.route("/get")
def get_bot_response():
userText = request.args.get('query')
return str(recommend.get_response(userText))
Actually I was surprised with the result after implemented this solution in a small project wide hackathon event. So I share this idea and the source code, hope it can help you.